Thanksgiving Special 🦃: GANs are Being Fixed in More than One Way
In the spirit of thanksgiving, let me start by thanking all the active commenters on my blog: you are always very quick to point out typos, flaws and references to literature I overlooked.
This post is basically a follow-up my earlier post, "GANs are broken in more than one way". In this one, I review and recommend some additional references people pointed me to after the post was published. It turns out, unsurprisingly, that a lot more work on these questions than I was aware of. Although GANs are kind of broken, they are also actively being fixed, in more than one way.
This was talked about before
In my post I focussed on potential problems that arise when we apply simultaneous gradient descent on a non-conservative vector field, or equivalently, a non-cooperative game.
These problems have been pointed out before by a number of authors before. As one example, (Salimans et al, 2017) talked about this and in fact used the same pathological example I used in my plot: the one which gives rise to the constant curl field:
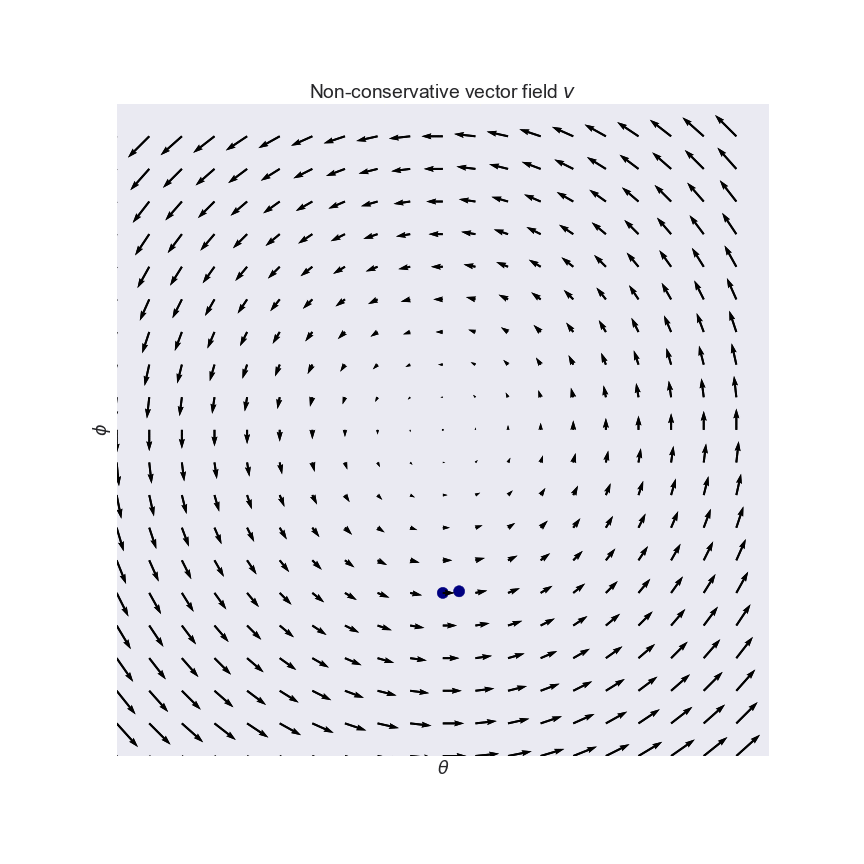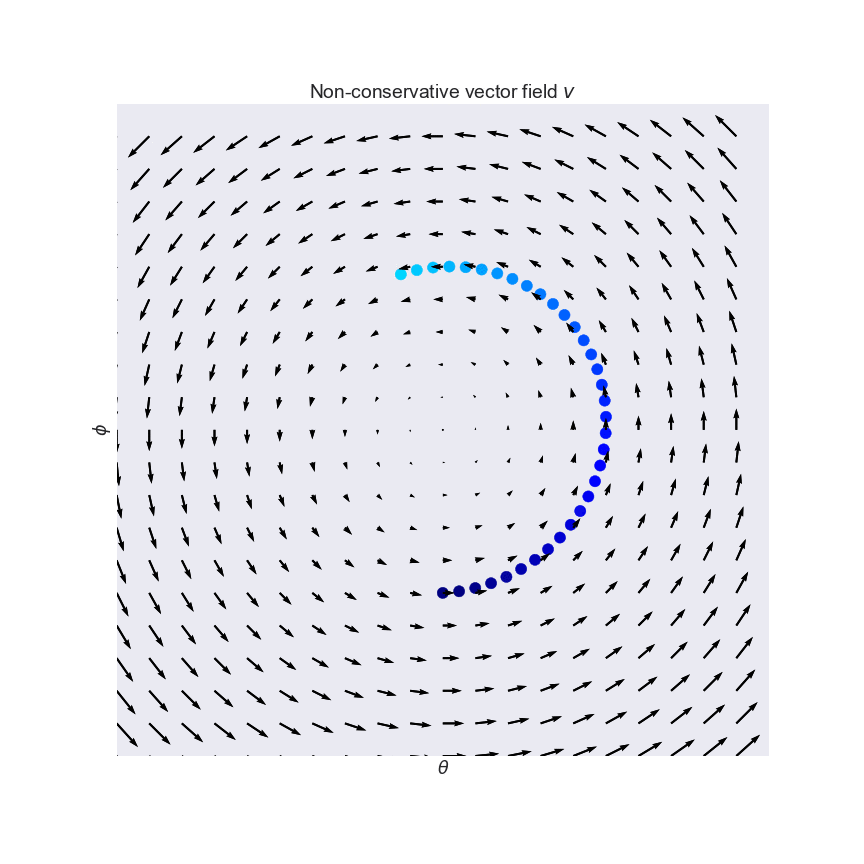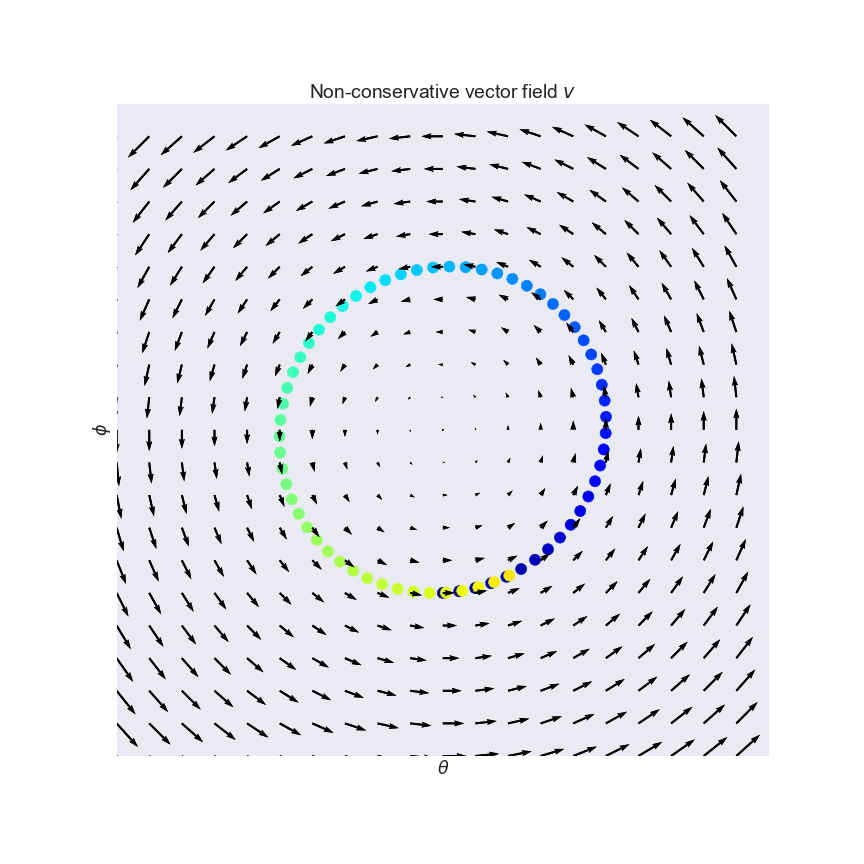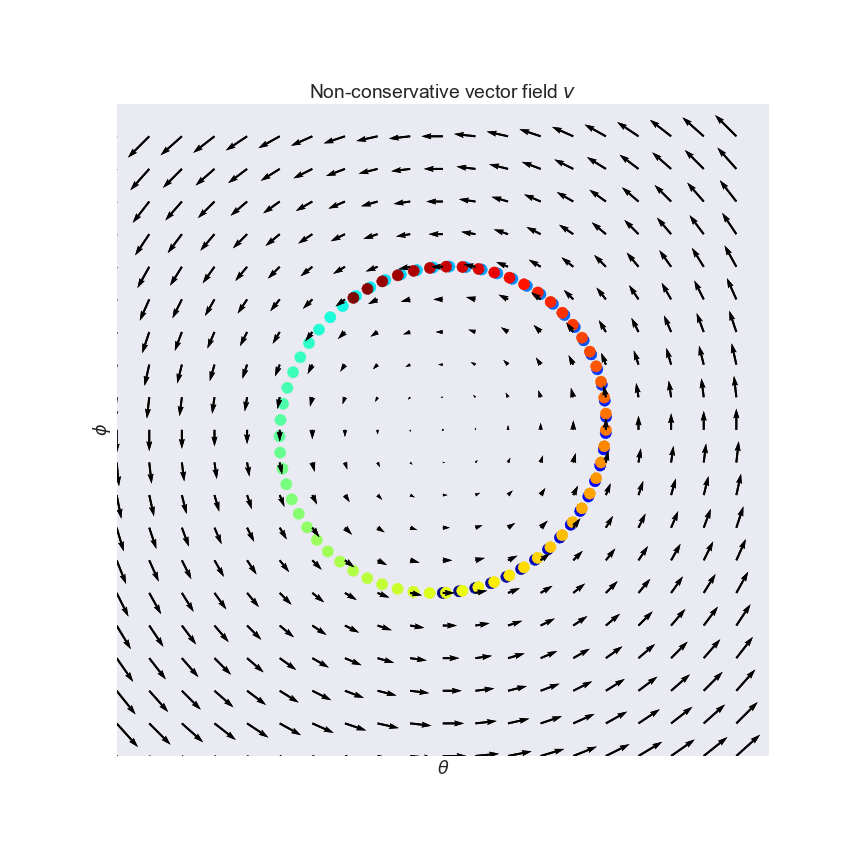
Pfau and Vinyals (2016) pointed out connections between GANs and actor critic methods. GANs and actor-critic methods are both notoriously hard to optimize, and the authors argue that these difficulties arise because of the same reasons. This means that two sets of people have been struggling to solve the same underlying problems, so it is reasonable to hope that we can learn from each other's innovations.
We don't always use simultaneous gradient descent
Many people pointed out that when using different variants of GANs, we don't actually use simultaneous gradient descent. Notably, in WGANs, and also often in normal GANs when using instance noise, we always optimize the discriminator until convergence before taking a step with the generator. This nested-loop algorithm has very different behaviour compared to simultaneous gradient descent. Indeed, you can aruge it converges inasmuch as the outer loop which optimizes the generator can be interpreted as vanilla gradient descent on a lower bound. Of course this convergence only happens in practice if the optimal discriminator is unique with respect to the generator, or at least if the solution is stable enough to assume that the outer loop indeed evaluates gradients of a deterministic scalar function.
(Heusel et al, 2017) propose another optimization strategy relying on updating the discriminator and generator at different time scales/learning rates. The authors prove that this algorithm always converges to a local Nash equilibrium, and this property holds even when using the Adam optimizer on top. This algorithm was later used successfully for training Coulomb GANs.
Gradient Descent GAN optimization is locally stable
In another great NIPS paper (Nagarajan and Kolter, 2017) study convergence properties of simultaneous gradient descent for various GAN settings. Using similar apparatus to the Numerics of GAN paper, they show that simultaneous GD is actually stable and convergent in the local neighborhood of the Nash equilibrium. On the other hand, it is also shown that WGANs have non-convergent limit cycles around the equilibrium (these are vector fields that make you go around in circles, like the example above). So, in WGANs we have a real problem with gradient descent. Based on these observations the authors go on to define regularization strategy that stabilizes gradient descent. Highly recommended paper.