
Unsupervised Learning by Predicting Noise: an Information Maximization View
This note is about a recent paper that was making rounds on the internet yesterday:
- Bojanowski and Joulin (2017): Unsupervised Learning by Predicting Noise
The method is simple yet powerful, and it is perhaps a bit surprising and conter-intuitive: it learns representations by mapping data to to randomly sampled noise vectors. The authors call the methods noise-as-target (NAT).
In this post, I'm going to assume you've at least skimread the paper and may have been left wondering what really is going on here. I will only add my perspective on it: I re-interpret the algorithm as a proxy to information maximisation. I think that if you start thinking about the algorithm it from this perspective, perhaps it becomes less surprising that the method actually works.
Summary
- I start from infomax: how to learn optimal compact representations by maximising the amount of information retained about the input data.
- I show why restricting the representation to the unit sphere - as it is done in the paper - makes sense in the Infomax framework.
- It's easy to show that if there is a deterministic representation that achieves uniform distribution, it maximises the infomax criterion. Therefore, if we believe such a solution exists, it makes sense to directly seek deterministic mappings that produce a distribution close to uniform.
- this is exactly what NAT does: it seeks a deterministic mapping whose marginal distribution is uniform on the unit sphere, and it does so by minimising a sort of empirical earth movers' distance from uniform samples.
- finally, I talk a bit about convergence of the stochastic Hungarian algorithm used in the paper for updating the assignment matrix.
Learning representations by maximising information
Let's say we are trying to learn a compact representation of data $x_n$ drawn i.i.d. from some distribution $p_X$. In general, the representation can be described as a random variable $z_n$ that is sampled conditionally i.i.d. fashion from some parametric conditional distribution $p_{Z\vert X, \theta}$:
\begin{align}
x_n &\sim p_{X}\\
z_n &\sim p_{Z\vert X=x_n, \theta}
\end{align}
In variational autoencoders, this $p_{Z\vert X, \theta}$ would be called the encoder or recognition model or amortized variational posterior. But, importantly, we now work directly with the encoder, without having to specify a generative distribution $p_{X\vert Z;\theta}$ explicitly.
The InfoMax principle says that a good representation is compact (in terms of it's entropy) while it simultaneously retains as much information about the input $X$ as possible. (see e.g. Chen et al, 2016 - InfoGAN, Barber and Agakov, 2003). This goal can be formalised as follows:
$$
\theta^{\text{infomax}} = \operatorname{argmax}_{\theta:\mathbb{H}[p_{Z;\theta}] \leq h} \mathbb{I}[p_{X,Z;\theta}],
$$
where $\mathbb{I}$ denotes mutual information and $\mathbb{H}$ the Shannon's entropy. I also introduced the following notation for distributions:
\begin{align}
p_{Z;\theta} &= \mathbb{E}_{x\sim p_X} p_{Z\vert X=x,\theta} \\
p_{X,Z;\theta}(x,z) &= p_X(x) p_{Z\vert X=x;\theta}(z\vert x)
\end{align}
In real-valued spaces, this optimisation problem can be ill-posed, and it has a few problems:
- The marginal entropy of the representation is hard to estimate in the general case. We need a smart way to implement the restriction $\mathbb{H}[p_{Z;\theta}]\leq h$ without actually having to compute the entropy.
- If the representation has deterministic and invertible components, the mutual information ends up infinite (in continuous spaces), and the optimisation problem becomes meaningless. To make the optimisation problem meaningful one needs to ensure that the pathological invertible case is never reached.
To address these problems, we can make the following changes:
- Firstly, let's restrict the domain of $Z$ to a finite volume (finite Lebesgue measure) subset of $\mathbb{R}^d$. This way, the differential entropy $\mathbb{H}[p_{Z;\theta}]$ is always upper bounded by the entropy of the uniform distribution on that domain. To be consistent with the paper, we can limit the domain of the representation to the unit Euclidean sphere $|z|_2^2=1$.
- Secondly, let's consider maximising the information between $x$ and the noise-corrupted representation $\tilde{z} = z + \epsilon$ where $\epsilon$ is i.i.d. noise. I'm going to assume that $\epsilon$ follows a spherical distribution for simplicity. What this added noise does in practice is it places an upper bound on the predictability of $x$ from any given $\tilde{z}$ (or the an upper bound on the invertibility of the representation) thereby also limiting the mutual information to well-behaved, finite values. Our optimization problem thus becomes:
$$
\operatorname{argmax}_{\theta: \mathbb{P}_{Z;\theta}(|z|_2^2=1)=1} \mathbb{I}[p_{X,\tilde{Z};\theta}],
$$
This loss function makes a intuitive sense: you are trying to map your inputs $x_n$ to values $z_n$ on the unit sphere, potentially in a stochastic fashion, but in such a way that the original datapoints $x_n$ are easily recoverable (under the log-loss) from $\tilde{z}_n$ which is a noisy version of $z_n$ . In other words, we seek a representation that is in some sense robust to additive noise.
Deterministic and uniform representations
It is not hard to show that if there is at least a single representation $p_{Z\vert X;\theta}$ which has the following two properties:
- $z_n$ is a deterministic function of $x_n$, and
- $p_{Z;\theta}$ is the uniform distribution on the unit sphere,
then this $p_{Z\vert X;\theta}$ is a global maximizer of the InfoMax objective.
Crucially, this deterministic solution may not be unique, there may be an infinite number of equally good representations, especially when $\operatorname{dim}(z)\ll \operatorname{dim}(x)$. Consider the case when $X$ is a multivariate standard Gaussian, and the representation Z is a normalised orthogonal projection of $X$, i.e. for some orthogonal transformation $A$:
$$
z_n = \frac{Ax_n}{\sqrt{x_n^TA^TAx_n}}
$$
Marginally, Z will have uniform distribution on the unit sphere, and it is also a deterministic mapping, therefore $Z$ is a maximum information representation and it is equally good for any orthogonal $A$.
So, if we assume there is at least one deterministic and uniform representation of $p_X$, it makes sense to seek only deterministic representations, and to seek ones that map data to an approximately uniform distribution in representation space.
This is exactly what the noise as targets (NAT) objective is trying to achieve
The way NAT tries to achieve a uniform distribution in representation space is by minimising a kind of empirical earth mover distance: first, we randomly draw as many uniform random representations as we have datapoints - these are the $c_n$. Then we try to optimally pair each $c_n$ to a datapoint so that the mean squared distance between $c_n$ and the corresponding representation $z_m=f(x_m,\theta)$ is minimal. Once a pairing is found, the mean squared distance between paired representations and noise vectors can be thought of as a measure of uniformity - indeed it's a sort of empirical estimate of the Wasserstein distance between $p_Z$ and a uniform.
Is an InfoMax representation a good representation?
I've had too many conversations of this nature in the last few days at DALI: what is a good representation? What does unsupervised representation learning even mean? You can ask the same question about InfoMAX: is it a good guiding principle for finding good representations?
I don't think it is enough, in itself. For starters: you can transform your representation in arbitrary ways, and as long as your transformation is invertible, the mutual information should stay the same. So you can arbitrarily entangle or disentangle any representation using invertible transformations, without the InfoMAX objective noticing. Hence, the InfoMax criterion alone can't be trusted to find you disentangled representations, for example.
It is far more likely that the empirical success we see is the combination of ConvNets with the InfoMax principle. We optimise information only among representations that are easy to represent by a ConvNet. And it may be that the intersection of ConvNet-friendly representations with InfoMax representations somehow end up pretty useful.
Summary
I showed that the noise-as-targets (NAT) representation-learning principle can be interpreted as seeking InfoMax representations: representations of limited entropy that retain maximum information about the input data in a way that is robust to noise. A similar information-maximisation-based interpretation can be given to Exemplar-CNNs (Dosovitsky et al, 2014) which work by trying to guess the index of a datapoint from a noisy version of the datapoint. These algorithms often look very odd and counterintuitive when you first encounter them, reinterpreting them as information maximisation helps demistify them a bit. At least I think it helps me.
Bonus track: Notes on Stochastic version of earth-mover-distance
The difficulty in implementing the earth mover's distance in this literal form is that you need to find the optimal assignment between the two empirical distributions and that scales as $O(N^3)$ in the number of samples $N$. To sidestep this, the authors propose a 'stochastic' update to the optimal assignment matrix whereby the pairings are only updated one minibatch at a time.
Not that I expect this to be a big deal, but it's worth pointing out that this algorithm is prone to getting stuck in local minima. Let's assume parameters of the representation $\theta$ are fixed, and the only thing we want to update is the assignments. Let's consider a toy situation illustrated in the figure below:
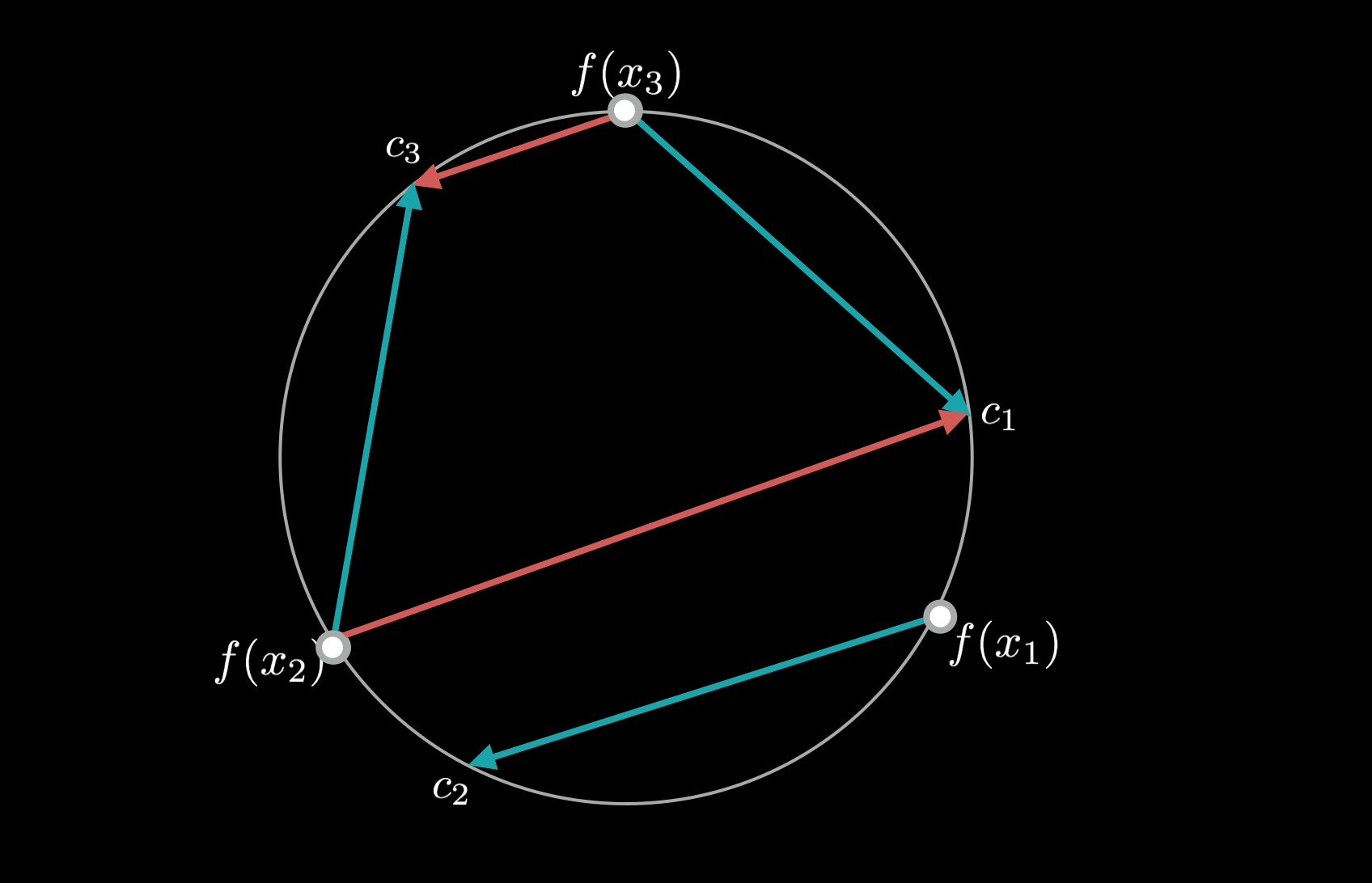
Consider three datapoints $x_1, x_2, x_3$, whose embeddings are equidistant and lie on the 2D unit sphere (my Mom - or any sane person - would probably call this a circle). Also consider three possible noise assignments $c_1, c_2, c_3$ which are also equidistant as shown. The optimal assignment would clearly pairing $x_1$ with $c_1$, $x_2$ with $c_2$ and $x_3$ with $c_3$. Let's assume our current mapping is suboptimal as shown by the blue arrows, and we are only allowed to update the assigmnent on minibatches of size 2. On a minibatch of size 2, there are only two possibilities to consider: either keep it as it was before, or swap things around, which is shown by the red arrows. In this toy example, keeping the previous assignment (blue arrows) is preferable to switchinig (red arrows) under the squared loss. Hence, the minibatch-based algorithm gets stuck in this "local minimum" with respect to minibatch updates.
This is not to say that the method doesn't work, especially as $\theta$ is also simultaneously updated, which may actually help getting the algorithm out of this local minimum anyway. Secondly, the larger the batchsize, the harder it may be to find such local minima.
The way to think about local minima of this stochastic Hungarian algorithm is to think of it as a graph: each node is a state of the assignment matrix (a permutation), and each edge corresponds to a valid update based on a minibatch. A local minimum is a node which has a lower cost than any node in its immediate neighbourhood. If we consider minibatches of size $B$, with a total sample size $N$, there will be $N!$ nodes in the graph and each node will have an out-degree of ${N \choose B}B!$. Therefore, the probability of any two nodes being connected will be $\frac{1}{(N-B)!}$. As we increase the batchsize $B$, the graph gets more and more connected, so local minima start to disappear.