InfoGAN: using the variational bound on mutual information (twice)
Many people have recommended me the infoGAN paper, but I hadn't taken the time to read it until recently. It is actually quite cool:
- Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, Pieter Abbeel (2016) InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
Summary of this note
- I show how the original GAN algorithm can be derived using exactly the same variational lower-bound that the authors use in this paper (see also this blog post by Yingzhen)
- However, GANs use the bound in the wrong direction and end up minimising a lower bound which is not a good thing to do
- InfoGANs can be expressed purely in terms of mutual information, and applying the variational bound twice: once in the correct direction, once in the wrong direction
- I believe that the unstable behaviour of GANs is partially explained by using the bound in the incorrect way
Mini-review
The InfoGAN idea is pretty simple. The paper presents an extension to the GAN objective. A new term encourages high mutual information between generated samples and a small subset of latent variables $c$. The hope is that by forcing high information content, we cram the most interesting aspects of the representation into $c$.
If we were successful, $c$ ends up representing the most salient and most meaningful sources of variation in the data, while the rest of the noise variables $z$ will account for additional, meaningless sources of variation and can essentially be dismissed as uncompressible noise.
In order to maximise the mutual information, the authors make use of a variational lower bound. This, conveniently, results in a recognition model, similar to the one we see in variational autoencoders. The recognition model infers latent representation $c$ from data.
The paper is pretty cool, the results are convincing. I found the notation and derivation a bit confusing, so here is my mini-review:
- I think the introduction, I don't think it's fair to say "To the best of our knowledge, the only other unsupervised method that
learns disentangled representations is hossRBM". There are loads of other methods that attempt this. - I believe Lemma 5.1 is basically a trivial application of the theorem of total expectation, and I really don't see the need to provide a proof for that (maybe reviewers asked for a proof).
- The notation in Eqn. (5) are a bit confusing. I don't think it makes sense to say $x \sim G(z,c)$. Instead I'd write Eqn. (5) as something like that:
$$
L_I(G,Q) = \mathbb{E}_{c\sim P(c),z\sim P(z)}[\log Q(c \vert G(c,z))] + H[c] \ldots
$$
My view on InfoGANs
I think there is an interesting connection that the authors did not mention (frankly, it probably would have overcomplicated the presentation). The connection is that original GAN objective itself can be derived from mutual information, and in fact, the discriminator $D$ can be thought of as a variational auxillary variable, exactly the same role as the recognition model $q(c\vert x)$ in the InfoGAN paper.
The connection relies on the interpretation of Jensen-Shannon divergence as mutual information (see e.g. Yingzen's blog post). Here is my graphical model view on InfoGANs that may put things in a slightly different light:
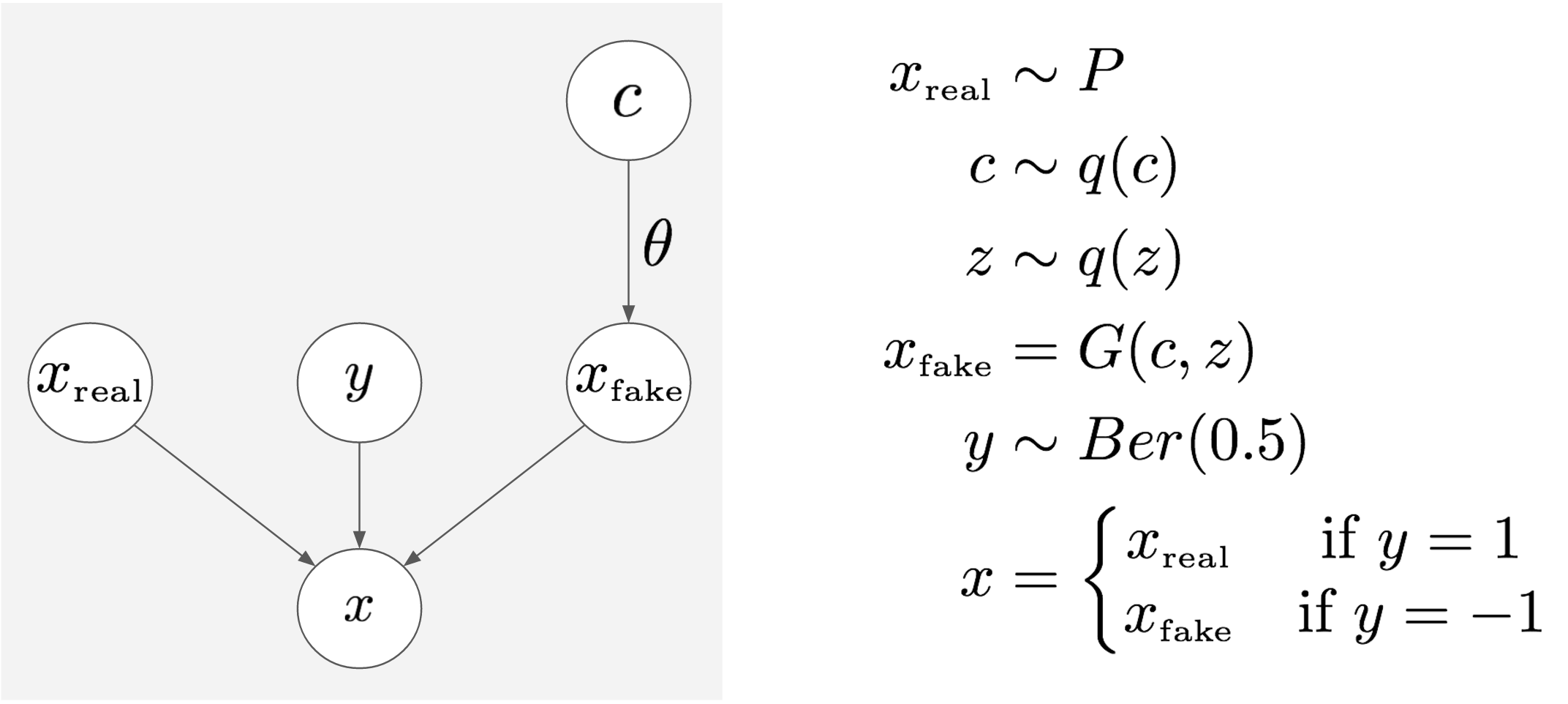
Let's consider the joint distribution of a bunch of varibles:
- $c$ is some latent variable, which is sampled from a prior $q(c)$.
- $x_{fake}$ is a synthetic sample we draw from the generator, conditioned on $c$. When generating $x_{fake}$, additional noise variables $z$ provide for non-deterministic behaviour. In the graph above I don't show $z$, instead I think it's better to think of the problem with $z$ marginalised out, and $x_{fake}$ to be sampled from some conditional distribution $q(x_{fake}\vert c;\theta)$, which is parametrised by $\theta$.
- $x_{real}$ is a real data sample
- $y$ is a binary label, a coinflip, sampled from a Bernoulli distribution with parameter $0.5$
- $x$ is a datapoint that in the GAN world the discriminator would receive: depending on $y$, it's either a copy of $x_{real}$ or $x_{fake}$.
In this big joint distribution of all the things, everything is fixed, except for the generator's parameter $\theta$. In this world, the idealised InfoGAN loss function for $\theta$ is this:
$$
\ell_{infoGAN}(\theta) = I[x,y] - \lambda I[x_{fake},c]
$$
Just a reminder, the vanilla GAN objective would be:
$$
\ell_{GAN}(\theta) = I[x,y]
$$
- the first term tries to minimise the mutual information between $x$ and the label $y$ that tells us whether it's real or fake. The idea is simple: if $x_{real}$ and $x_{fake}$ come from the same distribution, it should be impossible to guess the value of $y$ better than chance, hence the mutual information would be $0$. This information term is exactly the same as the Jensen-Shannon divergence between the distribution of $x_{real}$ and $x_{fake}$.
- the second term is the one introduced in the InfoGAN paper, which tries to ensure that $c$ effectively explains most of the variation in the fake data $x_{fake}$.
The variational bound on mutual information
I think it's worth showing how one would come up with this variational bound on the mutual information. Let's say we'd like to lower bound the mutual information between two random variables $X$ and $Y$, with joint distribution $p(x,y)$:
\begin{align}
I[X,Y] &= H[Y] - \mathbb{E}_{x} H[Y\vert X=x]\\
&= H[Y] + \mathbb{E}_{x} \mathbb{E}_{y\vert x} \log p(y\vert x)\\
&= H[Y] + \mathbb{E}_{x} \mathbb{E}_{y\vert x} \log \frac{p(y\vert x) q(y\vert x)}{q(y\vert x)}\\
&= H[Y] + \mathbb{E}_{x} \mathbb{E}_{y\vert x} \log q(y\vert x) + \mathbb{E}_x \mathbb{E}_{y\vert x} \log \frac{p(y\vert x)}{q(y\vert x)}\\
&= H[Y] + \mathbb{E}_{x} \mathbb{E}_{y\vert x} \log q(y\vert x) + \mathbb{E}_{x} KL[p(y\vert x)|q(y\vert x)] \\
&\geq H[Y] + \mathbb{E}_{x} \mathbb{E}_{y\vert x} \log q(y\vert x)
\end{align}
Here, $q(y|x;\psi)$ is a parametric probability distribution was introduced as an auxillary variable. It has to be a probability distribution for the $KL$ divergence to be non-negative therefore for the bound to hold. The bound is tight if $q$ is exactly the same as the conditional distribution $p(y\vert x)$ for all $x$.
We can write this lower bound alternatively in the following way:
$$
I[X,Y] = \max_{q} \left\{H[Y] + \mathbb{E}_{x,y} \log q(y\vert x) \right\}
$$
And if we restrict $q$ to a parametric family we can say that the following lower bound holds:
$$
I[X,Y] \geq H[Y] + \max_{\psi} \mathbb{E}_{x,y} \log q(y\vert x; \psi)
$$
GANs use bound in the wrong direction!
Let's see what happens if we apply the variational lower bound on the GAN objective function above.
\begin{align}
\ell_{GAN}(\theta) &= I[x,y] \\
&\geq h(0.5) + \max_{\psi} \mathbb{E}_{x,y} \log q(y\vert x; \psi)\\
&= h(0.5) + \max_{\psi} \left\{ \mathbb{E}_{x_{real}} \log q(1\vert x; \psi) + \mathbb{E}_{x_{fake}} \log q(0\vert x; \psi)
\right\},
\end{align}
where $h(0.5) = -\log 2$ is the binary entropy function evaluated at $0.5$.
If we further expand the definition of $x_{fake}$ and rename the variational distribution to $D(x) = q(1\vert x)$, we get a more familiar loss function for GANs, similar to Equation (1) in the paper:
$$
\ell_{GAN}(\theta) + h(0.5) \geq \max_{\psi} \left\{ \mathbb{E}_{x
\sim P_{data}} \log D(x,\psi) + \mathbb{E}_{c,z} \log (1 - D(G(c,z,\theta),\psi)) \right\}
$$
Now, the main problem is with this derivation is that we were supposed to minimise $\ell_{GAN}$, so we really would like an upper bound instead of a lower bound. But the variational method only provides a lower bound. Therefore,
GANs minimise a lower bound, which I believe accounts for some of their unstable behaviour
InfoGANs use the bound twice
Recall that the idealised InfoGAN objective is the weighted difference of two mutual information terms.
$$
\ell_{infoGAN}(\theta) = I[x,y] - \lambda I[x_{fake},c]
$$
To arrive at the algorithm the authors used, one uses the bound on both mutual information terms.
- When you apply the bound on the first term, you get a lower bound, and you introduce an auxillary distribution that ends up being called the discriminator. This application of the bound is wrong because it bounds the loss function from the wrong side.
- When you apply the bound on the second term, you end up upper bounding the loss function, because of the negative sign. This is a good thing.
The combination of a lower bound and an upper bound means that you don't even know which direction you're bounding or approximating the loss function from anymore, it's neither an upper or a lower bound.