When is Machine Learning Worth it?
Last week I had an interesting exchange with a friend about integrating machine learning complex technology pipelines. To make his point he referred to this recent paper by Google: Machine Learning: The High Interest Credit Card of Technical Debt. In a nutshell, machine learning comes at a price. It introduces dependency on training data, it is hard to debug, test, maintain, and hard to guarantee performance in every scenario. I think at the heart of this is the fact that we are yet to come up with proper software engineering framework to deal with the unique challenges of solving problems in the machine learning way.
When you come out of a PhD in statistical machine learning, everything looks like a statistical machine learning problem. Most of these problems can indeed be solved by ML. But the real question is which problems should be solved by ML. Having worked in technology as a data scientist, I now agree with my friend that most problems that can be solved with ML are often best solved without ML. But I also think there are some exceptions to this rule, and it's important to analyse your problem to figure out what applies to you.
Frisbee catching scenario
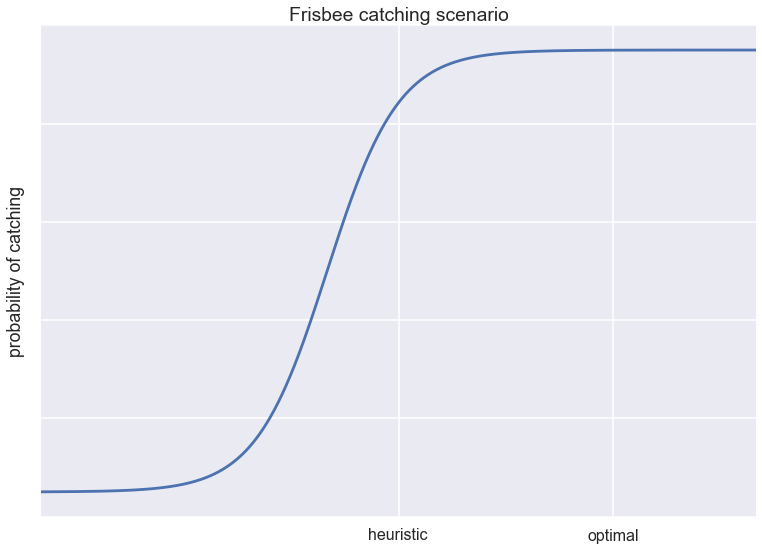
Another paper my friend referred me to is this anecdote about the dog and the frisbee. The main idea is as follows: Catching a frisbee is a very hard problem. If one wanted to model it with physics, chances are the model would get very complex very quickly. Similarly, good luck solving it with AI/deep learning, you will need loads of data and very complex models.
However, there is a very simple heuristic that works most of the time: "run at a speed so that the angle of gaze to the frisbee remains roughly constant". This simple heuristic agrees with how dogs and humans seem to catch frisbees in real life. The morale of the story is:
sometimes the best way to solve complex problems is to keep them simple
In my experience, this anecdote applies to most problems in data science. Do you need a recommender system? Try the simple people who have bought this also bought that heuristic first before thinking about machine learning. If you need to classify or predict things, try logistic regression with simple features. This annoys the hell out of data scientists who are fresh out of a PhD in machine learning, but linear regression actually does the job in 90% of the cases. Implementing a linear classifier in production is super-easy and very scaleable.
I think about these problems in terms of utility functions, as is shown in the figure above. Let's say the utility or value of any solution is described as a sigmoidal function of some kind of raw performance metric. In the frisbee catching scenario, the utility would be the probability of catching the frisbee. In frisbee catching-like data science problems, a heuristic already achieves pretty good results, and so any complex machine learning solution would be trying to make a big impact in the saturated regime of the utility function.
The hard problems
Of course, there are hard problems where we could not get any simple heuristics working yet, where the only answer today seems to be machine learning. An example of this would be speech recognition.
I think of the overall utility of a speech recognition system as a steep sigmoidal function of the underlying accuracy. Below a threshold accuracy of say 95%, the system is practically useless. Around 95% things start getting useful. Once this barrier is passed, the systems feel near perfect and people start adopting it. This is illustrated in the figure below (this is just an illustrative figure, the numbers don't mean anything). We have made a lot of progress recently, but breakthroughs in machine learning techniques were needed to get us here. Once we are past the steep part of the curve, improving existing systems will start to have diminishing returns.
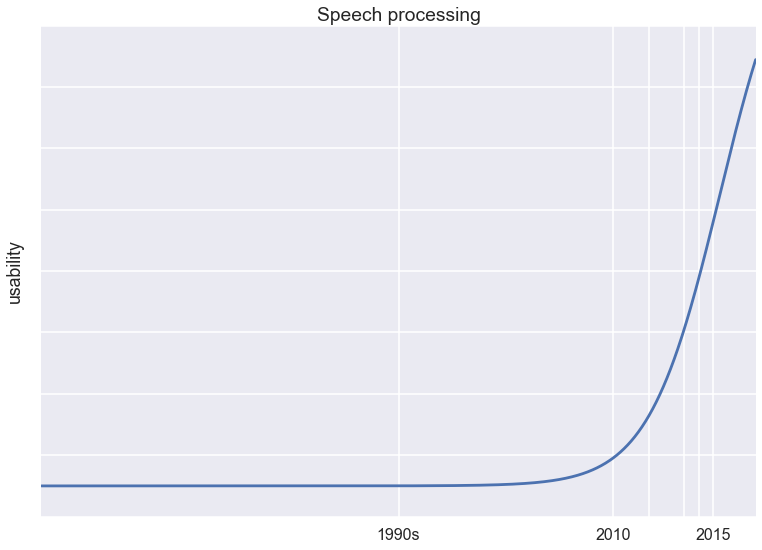
I think there are a number of problems that fall into this category of hard problems: object recognition, speech recognition, machine translation, image caption generation, action recognition in video, etc. These are some of the most actively researched applications of machine learning today, and our only hope to solve it with our knowledge today is to use lots of data in complex deep learning systems. In these cases, using machine learning as part of the technology not only makes sense, but is pretty much the only way to get through to the 'useful' regime.
The linear regime: the money making scenario
Finally, I think there is a third type of application, which I call the money making scenario. In these scenarios the utility function is not too steep, and we are currently in a linear regime, a bit like this below:
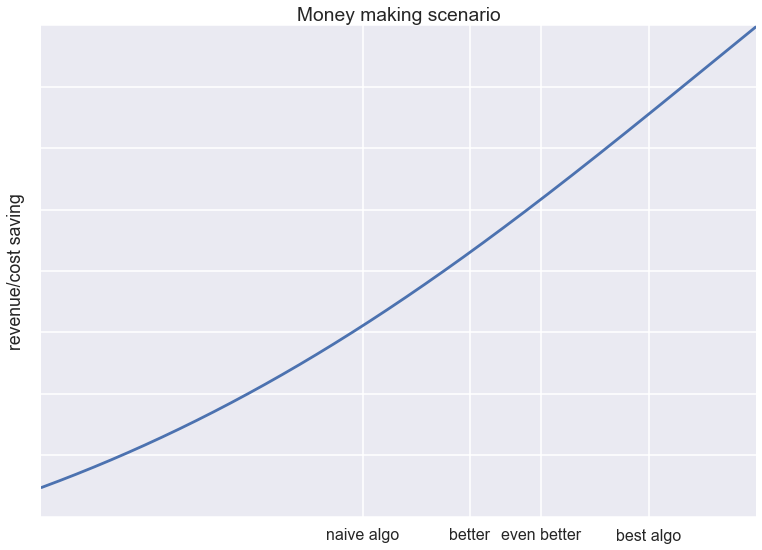
These are applications like the matching algorithm of an otherwise healthy ad network, an algorithmic trading system, the recommender engine of a very high-volume e-commerce site, or data compression. In these applications the revenue or cost saving scales nearly linearly with the raw performance of our system. Crucially, whether this is true in your case is not just a function of the application, it also depends on other aspects of your business and objectives. For example, improving a recommender system only has linear effect on revenues once you have a high volume of visitors and purchases. A better recommender engine is unlikely to help you with user acquisition if you don't have any users.
If you are in a linear regime like this, you can make an informed judgment about whether investing in machine learning and putting up with the associated headaches makes sense for you or not.