The Two Kinds of Uncertainty an AI Agent Has to Represent
AI agents have to act in non-deterministic environments: a self-driving car cannot be 100% confident what other cars or pedestrians are going to do;in medicine, the measurable data are often insufficient to predict the outcome of a treatment with full certainty. It kind of goes without saying that AI agents have to represent these uncertainties somehow to act optimally.
What's perhaps less clear to people is that there are two markedly different kinds of uncertainty: model uncertainty and environment uncertainty. These influence optimal behaviour in completely different ways.
Environment and model uncertainty
Environment uncertainty is uncertainty that is a property of the observable environment. Perhaps the simplest example of environment uncertainty is a coin flip. When we flip a coin, the outcome will be heads or tails with 50:50 chance.
Model uncertainty on the other hand is our agent's own lack of knowledge about the environment. For example, the agent is in a castle and has to choose between two doors: one of them leading to the princess. Before it tried a door, it cannot be certain whether the princess will be there or not. There is no environment uncertainty in this case, the princess is in one of the rooms, and if you try the same door twice, you'll get the same answer deterministically. The agent's uncertainty now stems from the fact that it has incomplete knowledge about the environment.
Of course, the two kinds of uncertanity can be present at the same time: the agent can be uncertain about how uncertain the outcome of an action is. Crucially though, if you only look at the predictive probabilities, the two kinds of uncertainty cannot be disentangled: being uncertain about certain outcomes and being certain about uncertain outcomes may result in exactly the same predictions as to what might happen.
Why is this important?
If the only thing we care about is predictive probabilities, why does it matter to disentanlge model unertainty from the environment? Well, in some cases like classification it may not matter that much; but in certain cases it may make or break our method.
Exploration and Exploitation
One of the examples where knowing the difference is really important is reinforcement learning. In reinforcement learning (RL) an agent has to act in an environment so that it maximises it's long term utility or reward. Typically a RL agent has to balance between exploration and exploitation.
Exploration is learning more about the environment so the agent knows what the most valuable actions are. Once the agent knows enough it can just stick to the most valuable action sequences (policy) and keep performing those, this is called exploitation. Distinguishing between model and environment uncertainty is important because the agent's goal in exploration should be to reduce model uncertainty. It can't, however, reduce environment uncertainty, so it's pointless to even try. Therefore, my prediction is that in the near future, we'll see a lot more model-based reinforcement learning agents relying on Bayesian deep networks.
A similarly important subproblem is active learning, where the agent learns to classify objects, and it also proactively selects unlabelled examples to be labelled by a human expert. Once it discovers that certain types of samples cannot be confidently labelled even by a human, it should stop trying to get those labelled. This is why naive entropy-based approaches to active learning such as maximum entropy sampling tend to fail
ConvNets that cannot be fooled
Representing uncertainty is also important in the simple case of classification. Although deep convolutional neural networks do deal with uncertainty (they output a confidence or probability for each class label), they typically do not distinguish between model and environment uncertainty.
This results in ConvBets being overly confident when classifying objects that it has not seen before. This is referred to as out-of-sample performance. Even worse, convnets can be easily tricked into misclassification by adding cleverly chosen small perturbations to correctly classified images.
See the following example taken from Andrej Karpathy's blog post on breaking convnets. Here, an image of a panda is correctly classified as panda by the network. However, when we add a tiny bit of "noise" to the image, the network now predicts very confidently it's a gibbon. There are more examples of these so called adversarial examples in this paper by Szegedy et al.
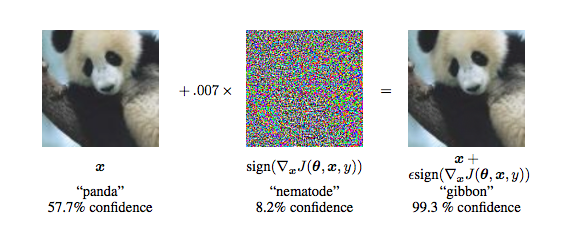
Although I haven't done experiments with this, my hypothesis would be that Bayesian ConvNets, where model uncertainty is explicitly represented would be less prone to such overconfident misclassification. Implementing these is not even as hard as one would think, see for example Yarin Gal's massive post with interactive demos, or these two ICML 2015 papers: Blundell et al, Hernandez-Lobato et al.
Testing whether Bayesian neural nets are indeed less prone to being fooled by adversarial examples would be a post for another day (or someone else).