
Stereovision Autoencoder
This post outlines a hypothesis, an idea for training a neural network in an unsupervised way to learn better representations of natural objects from visual input. I call this the stereovision autoencoder. Here is how it would work:
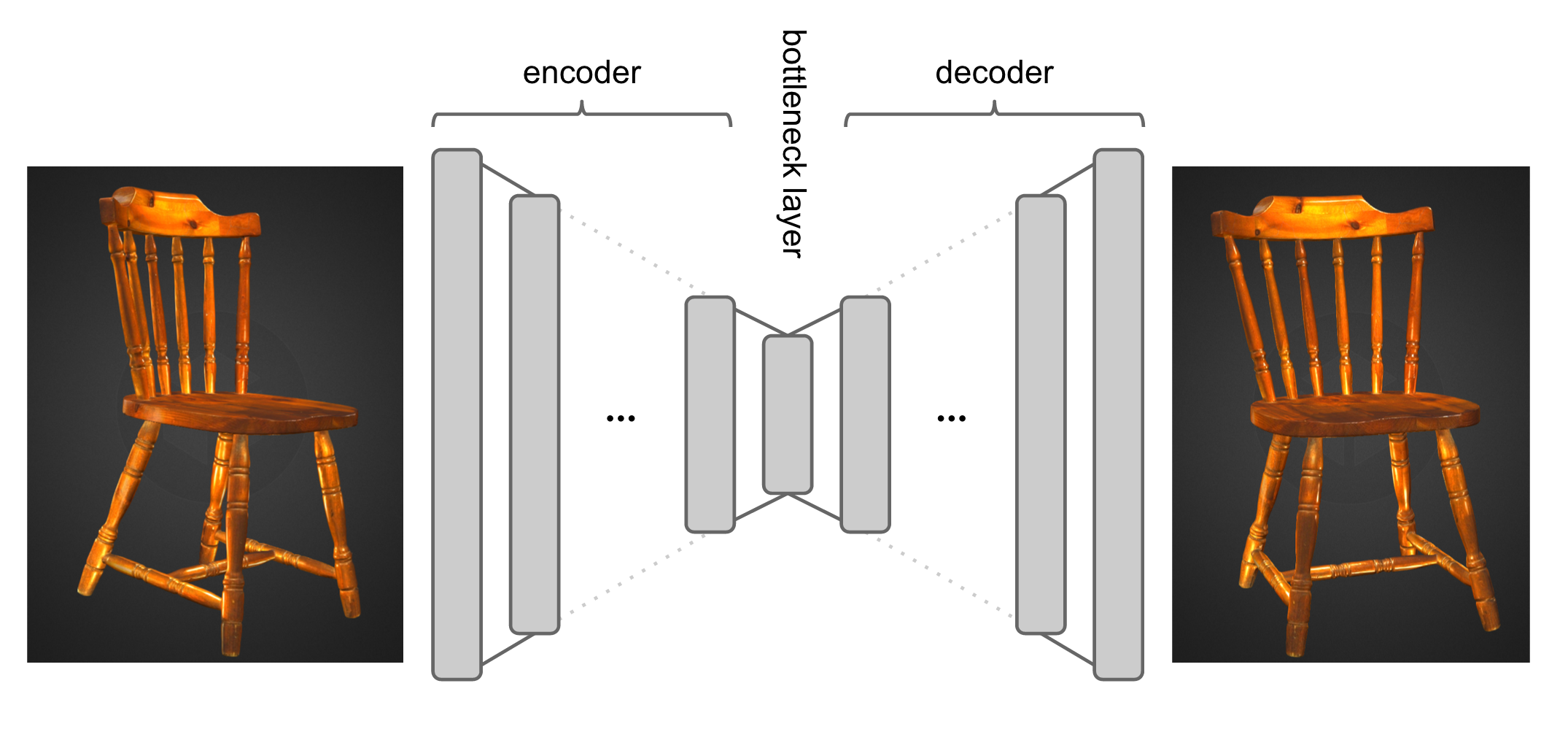
The core of the idea is to train an auto-encoder to reconstruct not the image it was fed, but an image of a 3D rotated version of the same object. A large repository of 3D assets like SketchFab could be used to generate a pretty OK sized training set. An example of a 3D asset I'm thinking about cold be this 3D scanned model of my 3 motnhs old baby boy:
Huba 3D by Ferenc Huszar on Sketchfab
Training
In terms of actual training method I would imagine doing something like this:
- start with a denoising autoencoder pretrained on still images in an unsupervised fashion. I think this is necessary, because the 3D asset database won't be large enough to learn all kinds of textures and abstract objects well.
- take a bunch of real-world 3D models from SketchFab, and generate pairs of stills $x_i, y_i$ in such a way that $y_i$ always shows $d$ degree rotation of $x_i$ in a 3D space.
- take the pretrained neural network, and train the autoencoder to reconstruct $y_i$ from $x_i$. The biological analogue of this would be learning to reconstruct what your left eye sees from what your right one sees. This is why I call this method stereovision autoencoder
- see what happens, eventually publish paper with mandatory cat neuron reference
Of course, there are variations to this, and I really don't know what would work. Perhaps one should start with $0$ degrees rotation, and gradually increase the level of rotation with each epoch. Or perhaps the camera angles should be given to the decoder network as an extra input. Perhaps when depth sensors become mainstream in consumer electronics, the depth information stored in photos will make this technique obsolete. Who knows? But intuitively I feel like there is something in there because:
if you really understand what an object is, you can imagine what it would look like if you looked at it from another angle
Biological motivation
A lot of machine learning is motivated by biology: we try to understand how the brain does certain things and use that to guide development of new methods. This is particularly true in the field of deep learning and neural networks, where the whole concept originates from the desire to copy the brain.
I don't think biological inspiration should be the primary driver for designing machine learning methods, but sometimes it can highlight patterns. Let's look at the main difference between how a human perceives the visual world, and how something like a deep convolutional neural network perceives the world. There are a couple massive differences, the main ones I can think of are:
- video: a person typically perceives a constant video feed, whereas modern ML methods are often trained on still images under the i.i.d. assumption. This is exploited computationally in algorithms such as slow feature analysis.
- active vision: the human eye does not perceive static rectangular images, rather the image is mapped to a variable resolution fovea, and vision is actually an active process where we direct our attention to parts of an image via saccades. This is investigated in a computational framework for foveal glimpses
- stereovision: lastly, humans have two eyes, 99% of training cases our brain perceives, we have two images from slightly different angles.
My question is, when we're training deep neural nets with billions of i.i.d. images, are we not ignoring a lot of information that would normally be available to humans to learn from? Is it not exponentially easier to learn the concept of a cow, if you have stereovision input? Is it not exponentially easier to learn concepts if you can use temporal priors such as slow feature analysis.
Theoretical justification: generalised pseudolikelihood learning
In a previous blog post I talked about how denoising autoencoders can be understood in the framework of pseudolikelihood learning of generative models. That made me thinking about different ways pseudolikelihood learning could be generalised in this context. One can think of generalised autoencoder learning objectives that would all be special case of pseudolikelihood learning:
- giving an autoencoder half of the image, teaching it to reconstruct the other half
- superresolution autoencoder: teaching an autoencoder to reconstruct high resolution images from low resolution subsampled ones
You can think of the stereovision autoencoder as a special case pseudolikelihood learning as well. Think about learning about the joint distribution of all images taken of an object from various angles. If you approached this problem with pseudolikelihood, you would get something like the algorithm I just described.
So what do you think? Does this make sense?