Everything that Works Works Because it's Bayesian: Why Deep Nets Generalize?
The Bayesian community should really start going to ICLR. They really should have started going years ago. Some people actually have.
For too long we Bayesians have, quite arrogantly, dismissed deep neural networks as unprincipled, dumb black boxes that lack elegance. We said that highly over-parametrised models fitted via maximum likelihood can't possibly work, they will overfit, won't generalise, etc. We touted our Bayesian nonparametric models instead: Chinese restaurants, Indian buffets, Gaussian processes. And, when things started looking really dire for us Bayesians, we even formed an alliance with kernel people, who used to be our mortal enemies just years before because they like convex optimisation. Surely, nonparametric models like kernel machines are a principled way to build models with effectively infinite number of parameters. Any model with infinite parameters should be strictly better than any large, but finite parametric model, right? Well, we have been proven wrong.
But maybe not, actually. We Bayesians also have a not-so-secret super-weapon: we can take algorithms that work well, reinterpret them as approximations to some form of Bayesian inference, and voila, we can claim credit for the success of an entire field of machine learning as a special case of Bayesian machine learning. We are the BORG of machine learning: eventually assimilate all other successful areas of machine learning and make them perfect. Resistance is futile.

We did this before: L1 regularisation is just MAP estimation with sparsity inducing priors, support vector machines are just the wrong way to train Gaussian processes. David Duvenaud and I even snatched herding from Max Welling and Alex Smola when we established herding is just Bayesian quadrature done slightly wrong.
But so far, we just couldn't find a way to claim credit for all of deep learning. Some of us tried to come through the back-door with Bayesian neural networks. It helps somewhat that Yann LeCun himself has written a paper on the topic. Yarin managed to claim dropout is just variational inference done wrong. But so far, Bayesian neural networks are just a complementary to existing successes. We could not so far claim that deep networks trained with stochastic gradient descent are Bayesian. Well, fellow Bayesian, our wait may be over.
Why do Deep Nets Generalise?
HINT: because they are really just an approximation to Bayesian machine learning.
One of the hottest topics at ICLR this year was generalisation in deep neural networks, and it seems to continue with a number of NIPS submissions. If you're not aware of this trend, read up on it, it's pretty interesting. It turns out, neural networks by themselves are indeed the stupid, dumb, highly overparametrised black-boxes we always said they were after all. People did an experiment (Zhang et al, 2017): you shuffle all labels in your training dataset - removing all information between inputs and labels - and the network will happily overfit to this complete garbage and achieve zero training error. If you have completely random labels, surely the only way to learn them is by memorizing each example and basically learning a sort of look-up-table. If you learn by memorization, you didn't really learn anything about generalisation in your data, your generalisation error will be huge. Related observations were made by Krueger et al, (2017). See Also Ben Recht's ICLR slides
So what is it - if not the network itself - that makes deep network training generalise? It appears to be that stochastic gradient descent may be responsible. (Keskar et al, 2017) show that deep nets genealise better with smaller batch-size when no other form of regularisation is used. And it may be because SGD biases learning towards flat minima, rather than sharp minima. This is something that (surprise-surprise) Hochreiter and Schmidhuber (1997) have worked on before. Most recently, (Wilson et al, 2017) show that these good generalisation properties afforded by SGD diminish somewhat when using popular adaptive SGD methods such as Adam or rmsprop. Finally, there is contradictory work by Dinh et al, (2017) who claim sharp minima can generalize well, too. See also (Zhang et al, 2017) and Jorge Nocedal's ICLR slides on the same topic.
In summary: The reason deep networks work so well (and generalize at all) is not just because they are some brilliant model, but because of the specific details of how we optimize them. Stochastic gradient descent does more than just converge to a local optimum, it is biased to favour local optima with certain desirable properties, resulting in better generalization. SGD itself, and the question of flat vs sharp minima, should therefore be of interest to Bayesians still trying to wrap their heads around the success of dumb deep networks.
We only need a small, vague claim that SGD does something Bayesian, and then we're winning.
Update: apparently, Bayesians have already started the process:
- Mandt, Hoffman and Blei (2017) Stochastic Gradient Descent as
Approximate Bayesian Inference
Flat minima and Minimum description length
So SGD tends to find flat minima, minima where the Hessian - and consequently the inverse Fisher information matrix - has small eigenvalues. Why would flat minima be interesting from a Bayesian pespective?
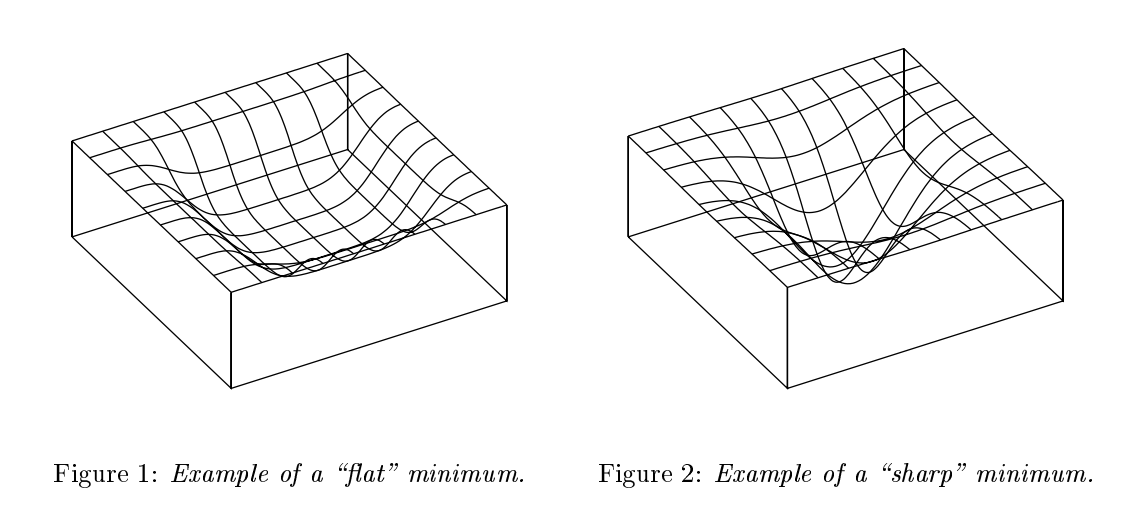
It turns out, (Hochreiter and Schmidhuber, 1997) motivated their work on seeking flat minima from a Bayesian, minimum description length perspective. Even before them, (Hinton and van Camp, 1993) presented the same argument in the context of Bayesian neural networks. The intuitive argument goals as follows:
If you are in a flat minimum, there is a relatively large region of parameter space where many parameters are almost equivalent inasmuch as they result in almost equally low error. Therefore, given an error tolerance level, one can describe the parameters at the flat minimum with limited precision, using fewer bits while keeping the error within tolerance. In a sharp minimum, you have to describe the location of your minimum very precisely, otherwise your error may increase by a lot.
Update: I removed the discussion of Jeffreys priors from here as people pointed out I was wrong.
Conclusions
Everything that works works because it's Bayesian. Maybe deep learning only works because it uses SGD, and maybe SGD is a rudimentary way of implementing Bayesian occam's razor. Whether you're a Bayesian or not, there's an interesting theory developing around generalisation in deep networks, and I think everyone - including Bayesians - should be aware of it. It seems like stochastic gradient descent and its tendency to seek out flat minima has a lot to do with why deep nets don't fail as miserably as Bayesians predicted them to. Seeking flat minima makes sense from a minimum description length perspective.
I should point out - if it's not clear - that the title, intro, and to some degree this conclusion were meant as a provocative joke. I'm pretty sure I'm going to get a lot of love for this post nevertheless. Please just don't take me too seriously.